تفسیرپذیری مکانیکی در پیشبینی نشانههای تکراری
توسعه مدلهای زبانی در مقیاس بزرگ، بهویژه ChatGPT، کسانی را که آن را تجربه کردهاند، از جمله خود من، از قدرت زبانی و توانایی قابل توجه آن در انجام وظایف مختلف شگفتزده کرده است. با این حال، بسیاری از محققان، از جمله من، در حالی که توانایی های آن را تحسین می کنند، خود را نیز گیج می کنند. حتی با وجود اینکه ما معماری مدل و مقادیر خاص وزن های آن را می دانیم، هنوز برای درک اینکه چرا یک توالی خاص از ورودی ها به دنباله خاصی از خروجی ها منتهی می شود، تلاش می کنیم.
در این پست وبلاگ، سعی خواهم کرد GPT2-small را با استفاده از قابلیت تفسیر مکانیکی در یک مورد ساده ابهام کنم: پیشبینی تکرار توکنها.
ابزارهای ریاضی سنتی برای توضیح مدلهای یادگیری ماشینی برای مدلهای زبانی مناسب نیستند.
SHAP را در نظر بگیرید، ابزاری مفید برای توضیح مدلهای یادگیری ماشین. این می تواند تعیین کند که کدام ویژگی به طور قابل توجهی بر پیش بینی کیفیت خوب شراب تأثیر گذاشته است. با این حال، مهم است که به یاد داشته باشید که مدلهای زبانی پیشبینیهایی را در سطح نشانه انجام میدهند، در حالی که مقادیر SHAP در درجه اول در سطح ویژگی محاسبه میشوند و به طور بالقوه برای توکنها نامناسب میشوند.
علاوه بر این، مدلهای زبان (LLM) دارای پارامترها و ورودیهای متعددی هستند که فضایی با ابعاد بالا ایجاد میکنند. محاسبه مقادیر SHAP حتی در فضاهای با ابعاد کم و حتی بیشتر از آن در فضای LLM با ابعاد بالا گران است.
با وجود تحمل هزینه های محاسباتی بالا، توضیحات ارائه شده توسط SHAP می تواند سطحی باشد. به عنوان مثال، دانستن اینکه اصطلاح “پاتر” به دلیل ذکر قبلی “هری” بیشترین تأثیر را بر پیش بینی نتیجه داشته است، بینش زیادی ارائه نمی دهد. این امر ما را در مورد بخشی از مدل یا مکانیسم خاصی که مسئول چنین پیشبینی است نامطمئن میسازد.
تفسیر مکانیکی رویکرد متفاوتی ارائه می دهد. نه تنها ویژگی ها یا ورودی های مهم را برای پیش بینی های مدل شناسایی می کند. در عوض، مکانیسمهای اساسی یا فرآیندهای استدلال را روشن میکند و به ما کمک میکند تا بفهمیم یک مدل چگونه پیشبینیها یا تصمیمگیریهای خود را انجام میدهد.
ما از GPT2-small برای یک کار ساده استفاده خواهیم کرد: پیشبینی دنبالهای از توکنهای تکرار شونده. کتابخانه ای که ما استفاده خواهیم کرد TransformerLens است که برای تفسیرپذیری مکانیکی مدل های زبان سبک GPT-2 طراحی شده است.
gpt2_small: HookedTransformer = HookedTransformer.from_pretrained("gpt2-small")
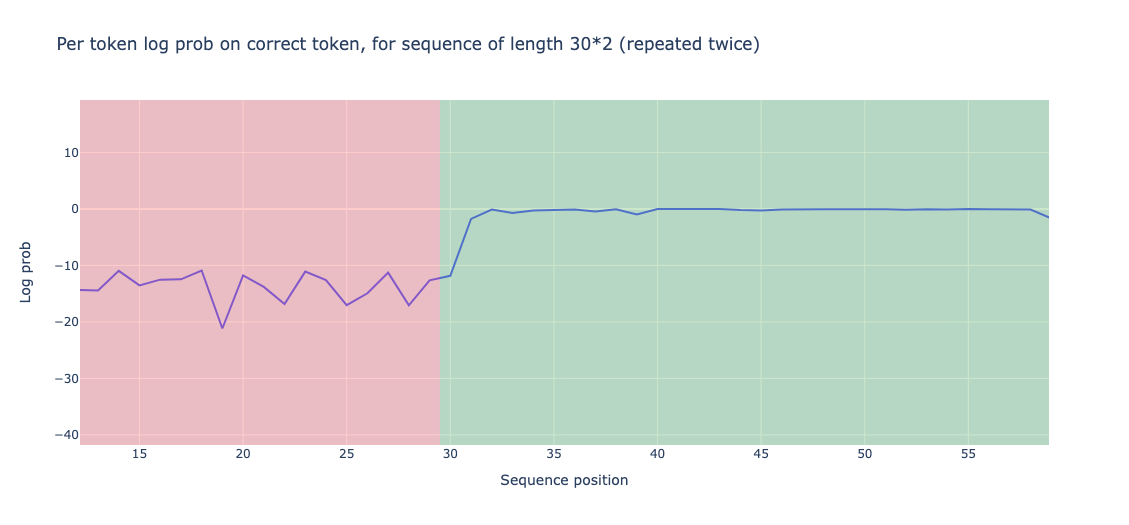
ما از کد بالا برای بارگذاری مدل GPT2-Small و پیشبینی توکنها در یک توالی تولید شده توسط یک تابع خاص استفاده میکنیم. این دنباله شامل دو دنباله یکسان از توکن ها و به دنبال آن bos_token است. یک مثال می تواند “ABCDABCD” + bos_token زمانی که seq_len 3 باشد. برای وضوح، ما به دنباله از start تا seq_len به عنوان نیمه اول و بقیه دنباله، به استثنای bos_token، به عنوان نیمه دوم اشاره می کنیم.
def generate_repeated_tokens(
model: HookedTransformer, seq_len: int, batch: int = 1
) -> Int[Tensor, "batch full_seq_len"]:
'''
Generates a sequence of repeated random tokensOutputs are:
rep_tokens: [batch, 1+2*seq_len]
'''
bos_token = (t.ones(batch, 1) * model.tokenizer.bos_token_id).long() # generate bos token for each batch
rep_tokens_half = t.randint(0, model.cfg.d_vocab, (batch, seq_len), dtype=t.int64)
rep_tokens = t.cat([bos_token,rep_tokens_half,rep_tokens_half], dim=-1).to(device)
return rep_tokens
وقتی اجازه میدهیم مدل روی توکن تولید شده اجرا شود، به یک مشاهدات جالب میرسیم: مدل در نیمه دوم دنباله به طور قابل توجهی بهتر از نیمه اول عمل میکند. این با احتمالات گزارش برای توکن های صحیح اندازه گیری می شود. به طور دقیق، عملکرد نیمه اول 13.898- است در حالی که عملکرد نیمه دوم 0.644- است.

همچنین میتوانیم دقت پیشبینی را محاسبه کنیم، که به عنوان نسبت توکنهای پیشبینیشده درست (آنهایی که با توکنهای تولید شده یکسان هستند) به تعداد کل توکنها تعریف میشود. دقت نیمه اول دنباله 0.0 است که جای تعجب نیست زیرا ما با توکن های تصادفی روبرو هستیم که معنای واقعی ندارند. در همین حال، دقت برای نیمه دوم 0.93 است که به طور قابل توجهی از نیمه اول پیشی گرفته است.
تعیین محل سر القایی
مشاهدات فوق را می توان با وجود مدار القایی توضیح داد. این زنجیرهای است که دنباله را برای نمونههای قبلی نشانه فعلی اسکن میکند، نشانهای را که قبلاً آن را دنبال میکرده شناسایی میکند و پیشبینی میکند که همان دنباله تکرار خواهد شد. به عنوان مثال، اگر با «A» روبرو شود، «A» قبلی یا نشانه ای بسیار شبیه به «A» را در فضای جاسازی شده اسکن می کند، نشانه بعدی «B» را شناسایی می کند و سپس نشانه بعدی را بعد از «A» پیش بینی می کند. “B” یا یک نشانه بسیار شبیه به “B” در فضای جاسازی باشد.

این فرآیند پیش بینی را می توان به دو مرحله تقسیم کرد:
- نشانه قبلی مشابه (یا مشابه) را شناسایی کنید. هر توکن در نیمه دوم دنباله باید به توکن «seq_len» که قبل از آن قرار داده شده «توجه» کند. به عنوان مثال، “A” در موقعیت 4 باید به “A” در موقعیت 1 توجه کند اگر “seq_len” 3 باشد.سر القایی“
- نشانه زیر “B” را شناسایی کنید. این فرآیند کپی کردن اطلاعات از نشانه قبلی (به عنوان مثال ‘A’) به نشانه بعدی (به عنوان مثال ‘B’) است. هنگامی که “A” دوباره ظاهر شد، از این اطلاعات برای پخش “B” استفاده می شود. میتوانیم سر توجه را که این وظیفه را انجام میدهد فراخوانی کنیم.نشانه سر قبلی“
این دو سر یک مدار القایی کامل را تشکیل می دهند. توجه داشته باشید که گاهی اوقات از عبارت “سر القایی” برای توصیف کل “مدار القایی” نیز استفاده می شود. برای آشنایی بیشتر با زنجیره القاء، مقاله In context Learning و فصل Induction را که شاهکار است به شدت توصیه می کنم!
حالا بیایید سر توجه و سر قبلی را در GPT2-small شناسایی کنیم.
کد زیر برای یافتن هد القایی استفاده می شود. ابتدا مدل را با 30 لات اجرا می کنیم. سپس میانگین قطر افست seq_len را در ماتریس مدل توجه محاسبه می کنیم. این روش به ما امکان میدهد میزان توجهی را که توکن فعلی به نشانهای که قبلا seq_len نشان داده میشود، اندازهگیری کنیم.
def induction_score_hook(
pattern: Float[Tensor, "batch head_index dest_pos source_pos"],
hook: HookPoint,
):
'''
Calculates the induction score, and stores it in the [layer, head] position of the `induction_score_store` tensor.
'''
induction_stripe = pattern.diagonal(dim1=-2, dim2=-1, offset=1-seq_len) # src_pos, des_pos, one position right from seq_len
induction_score = einops.reduce(induction_stripe, "batch head_index position -> head_index", "mean")
induction_score_store[hook.layer(), :] = induction_scoreseq_len = 50
batch = 30
rep_tokens_30 = generate_repeated_tokens(gpt2_small, seq_len, batch)
induction_score_store = t.zeros((gpt2_small.cfg.n_layers, gpt2_small.cfg.n_heads), device=gpt2_small.cfg.device)
rep_tokens_30,
return_type=None,
pattern_hook_names_filter,
induction_score_hook
)]
)
حالا بیایید به نتایج القایی نگاه کنیم. متوجه خواهیم شد که برخی از فصل ها مانند فصل 5 و فصل 5 دارای امتیاز القایی بالایی 0.91 هستند.

همچنین می توانیم الگوی توجه این فصل را نشان دهیم. متوجه یک خط مورب واضح در کنار افست seq_len خواهید شد.

به طور مشابه، ما میتوانیم هد توکن قبلی را شناسایی کنیم. به عنوان مثال، لایه 4 فصل 11 یک الگوی قوی برای توکن قبلی را نشان می دهد.

لایه های MLP چگونه نسبت داده می شوند؟
بیایید به این سوال نگاه کنیم: آیا لایه های MLP حساب می شوند؟ می دانیم که GPT2-Small شامل لایه های توجه و MLP است. برای بررسی این موضوع، من پیشنهاد میکنم از تکنیک ابلیشن استفاده شود.
همانطور که از نام آن پیداست، به طور سیستماتیک اجزای خاصی از مدل را حذف می کند و مشاهده می کند که چگونه عملکرد در نتیجه تغییر می کند.
خروجی لایههای MLP در نیمه دوم دنباله را با لایههای نیمه اول جایگزین میکنیم و مشاهده میکنیم که چگونه این کار بر تابع ضرر نهایی تأثیر میگذارد. با استفاده از کد زیر تفاوت بین اتلاف پس از تعویض خروجی های لایه MLP و افت اولیه نیمه دوم دنباله را محاسبه می کنیم.
def patch_residual_component(
residual_component,
hook,
pos,
cache,
):
residual_component[0,pos, :] = cache[hook.name][pos-seq_len, :]
return residual_componentablation_scores = t.zeros((gpt2_small.cfg.n_layers, seq_len), device=gpt2_small.cfg.device)
gpt2_small.reset_hooks()
logits = gpt2_small(rep_tokens, return_type="logits")
loss_no_ablation = cross_entropy_loss(logits[:, seq_len: max_len],rep_tokens[:, seq_len: max_len])
for layer in tqdm(range(gpt2_small.cfg.n_layers)):
for position in range(seq_len, max_len):
hook_fn = functools.partial(patch_residual_component, pos=position, cache=rep_cache)
ablated_logits = gpt2_small.run_with_hooks(rep_tokens, fwd_hooks=[
(utils.get_act_name("mlp_out", layer), hook_fn)
])
loss = cross_entropy_loss(ablated_logits[:, seq_len: max_len], rep_tokens[:, seq_len: max_len])
ablation_scores[layer, position-seq_len] = loss - loss_no_ablation
ما به یک نتیجه شگفتانگیز میرسیم: جدا از اولین نشانه، ابلیشن تفاوت منطقی قابلتوجهی ایجاد نمیکند. این نشان می دهد که لایه های MLP ممکن است سهم قابل توجهی در مورد توکن های تکراری نداشته باشند.

با توجه به اینکه لایههای MLP سهم قابلتوجهی در پیشبینی نهایی ندارند، میتوانیم به صورت دستی یک زنجیره القایی با استفاده از سر لایه 5، سر 5 و سر لایه 4، سر 11 بسازیم. به یاد داشته باشید که اینها سر القایی و قبلی هستند. سر نشانه ما این کار را با کد زیر انجام می دهیم:
def K_comp_full_circuit(
model: HookedTransformer,
prev_token_layer_index: int,
ind_layer_index: int,
prev_token_head_index: int,
ind_head_index: int
) -> FactoredMatrix:
'''
Returns a (vocab, vocab)-size FactoredMatrix,
with the first dimension being the query side
and the second dimension being the key side (going via the previous token head)'''
W_E = gpt2_small.W_E
W_Q = gpt2_small.W_Q[ind_layer_index, ind_head_index]
W_K = model.W_K[ind_layer_index, ind_head_index]
W_O = model.W_O[prev_token_layer_index, prev_token_head_index]
W_V = model.W_V[prev_token_layer_index, prev_token_head_index]
Q = W_E @ W_Q
K = W_E @ W_V @ W_O @ W_K
return FactoredMatrix(Q, K.T)
محاسبه بالاترین دقت 1 این طرح مقدار 0.2283 را به دست می دهد. این برای زنجیره ای که فقط از دو سر ساخته شده است بسیار خوب است!
برای پیاده سازی دقیق لطفا من را بررسی کنید نوت بوک.
![Read more about the article بلوتوث در ویندوز 10/11 به طور تصادفی قطع می شود [FIXED]](https://techpp.com/wp-content/uploads/2024/02/Random-Bluetooth-Disconnection-in-Windows-10-11.jpg)

